Share
When I teach activation functions, we cover the usual suspects—Sigmoid, Tanh, ReLU, etc.—but I also introduce activations like ELU, Swish, and SiLU. Students often ask, “Where are these even used?”
A great example is SD3.5, where SiLU (Sigmoid-weighted Linear Unit) play crucial roles. Here, SiLU is commonly paired with normalization layers like AdaLayerNorm and SD35AdaLayerNormZeroX. Large diffusion models like these require smooth gradient flows to ensure stable and high-quality image generation. The use of smoother activations like SiLU, in contrast to sharper ones like ReLU, enhances model stability and the synthesis of fine details, making them indispensable for advanced applications.
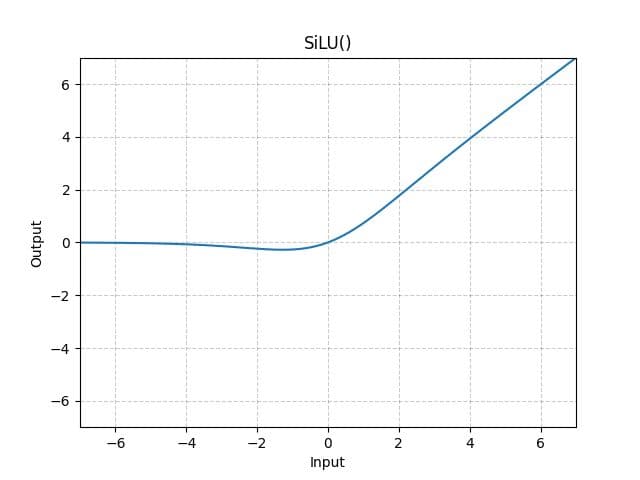
The SiLU function is defined as silu(x)=x∗σ(x), where σ(x) is the logistic sigmoid function. Notice how it resembles ReLU but is smoother at the origin, which facilitates better gradient flow.
Incorporate AI ML into your workflows to boost efficiency, accuracy, and productivity. Discover our artificial intelligence services.
View All
Explore how the SwiGLU activation function has become a key component in modern large language models and why it outperforms traditional alternatives.
A hands-on tutorial on using Physics-Informed Neural Networks to model the classic lid-driven cavity flow problem.
Breaking down Kolmogorov-Arnold Networks and understanding how they offer a fresh perspective on neural network architecture design.
© Copyright Fast Code AI 2026. All Rights Reserved