Share
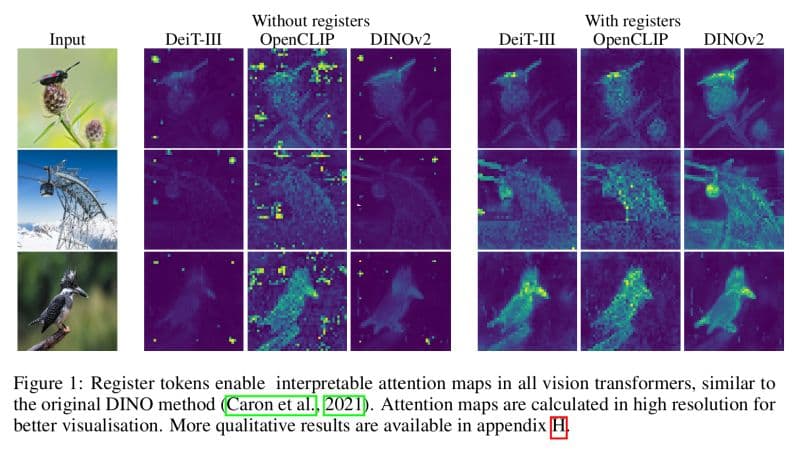
The outstanding paper at #ICLR 2024, "Vision Transformers Need Registers” by Dracet et al., which tackles the challenge in vision transformers (#ViTs) of high-norm tokens skewing attention towards uninformative background regions.
In traditional ViTs, each image patch is treated like a sequence before self-attention mechanisms. However, this often results emphasis on background noise, detracting from themodel’s ability to concentrate on salient features.
Introducing additional "register tokens" into the architecture. These tokens aren't derived from the image data but are included to accumulate and refine essential features across transformer layers. By balancing the attention mechanism, these registers help mitigate the impact of high-norm tokens and enhance the overall focus and efficacy of the model.
This approach not only improves clarity and relevance in image analysis but also sets a new standard for addressing common pitfalls in vision transformers, potentially revolutionizing how we tackle various image-based tasks.
Dive deeper into this transformative work and explore its implications for the future of computer vision: https://arxiv.org/abs/2309.16588
Incorporate AI ML into your workflows to boost efficiency, accuracy, and productivity. Discover our artificial intelligence services.
View All
How register tokens help Vision Transformers reduce background noise artifacts and improve feature map quality.
Why open-source AI is critical for preventing monopolization and ensuring equitable access to artificial intelligence.
A hands-on tutorial on using Physics-Informed Neural Networks to model the classic lid-driven cavity flow problem.
© Copyright Fast Code AI 2026. All Rights Reserved