A Convolutional Neural Network trained on the MNIST dataset when presented images from the Devanagari dataset will wrongly classify the Devanagari letter to one of the MNIST classes 0-9, usually with very high confidence. What can we do to fix this?
Share
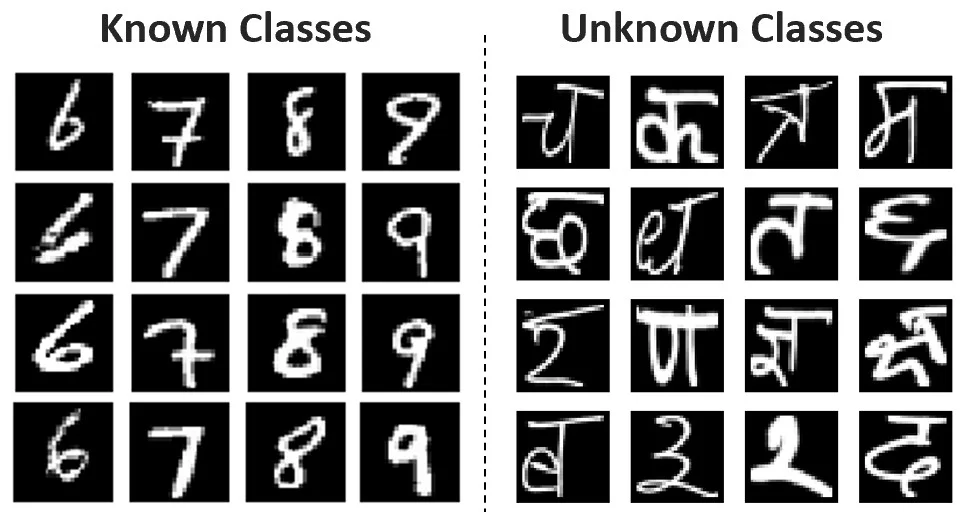
A Convolutional Neural Network (ConvNet) trained on the MNIST dataset when presented images from the Devanagari dataset will wrongly classify the Devanagari letter to one of the MNIST classes 0-9, usually with very high confidence. What can we do to fix this?
Systems trained without a background class can lead to nasty false positives when deployed in production. While most of the academic datasets such as PASCAL, MS-COCO or MNIST where algorithms are often evaluated, do not have this problem because all classes are known, it is a likely source of negative dataset bias and does not necessarily hold true in the real world where the negative space has near infinite variety of inputs that need to be rejected.
For example, let us look as this image below:
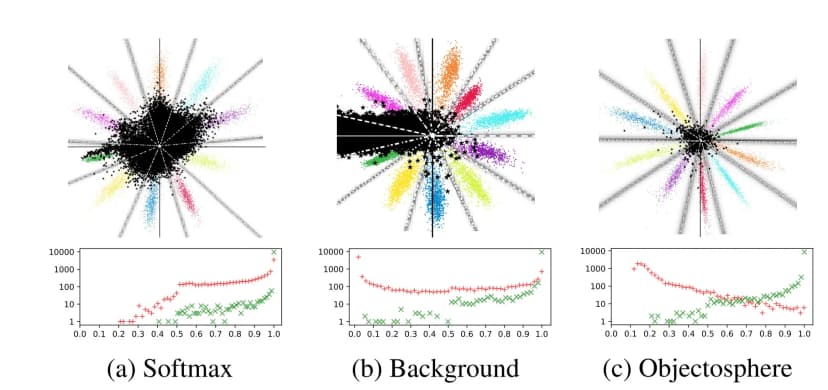
In the 3 scatter plots on the top row, the 10 different colors represent the 10 MNIST classes 0-9, and the black color represents the unknown Devanagari class. The softmax probability is plotted with the origin being zero, and the value increases to one as we go out radially along the lines.
In the plots on the bottom row are histograms of softmax probability values for samples of known MNIST data (Red) and unknown Devanagari data (red) with a logarithmic vertical axis.
As it can be clearly seen, in the plot (a), some of the samples from the Devanagari dataset have very high scores. Even when an additional unknown class is added in plot (b), some black dots falling in the 0-9 classes are still far away from the origin. In an application, a score threshold θ should be chosen to optimally to separate unknown from known samples. Unfortunately, such a threshold is difficult to find for either (a) or (b), however, a better separation is achievable with the Objectosphere loss (c) which I will describe next in this post.
The most common approach taken to deal with unknown classes to prevent false positives are by:
1. thresholding softmax, or
2. using an additional background, garbage or nota class.
However, they still have problems as shown in the plots (a) and (b) above. Dhamija et al. in the paper Reducing Network Agnostophobia from NeurIPS 2018 present a simple yet effective approach which leads to a better solution to this unknown class problem and the results can be seen in the plot (c) above. They achieve this using the Objectosphere loss.
In simple words, all they say is: do no use the additional background, garbage or nota class. Instead, force the unknown classes to output a uniform distribution. And, also force the magnitude of activations for known classes to be at least a margin m and that of unknown classes to be zero. Thats it!To understand it more formally, please check the equations (1) and (2) from their paper.
There are two kinds of unknowns - the known unknown and the unknown unknown. This method only works best for the known unknowns. E.g. in one experiment, for a MNIST classifier, they find that training with CIFAR samples as the unknowns does not provide robustness to unknowns from the samples of NIST Letters dataset. Whereas, training with NIST Letters does provide robustness against CIFAR images. This is because CIFAR images are distinctly different from the MNIST digits where as NIST letters have attributes very similar to them. This finding however is consistent with the well known importance of hard-negatives in deep network training.
Incorporate AI ML into your workflows to boost efficiency, accuracy, and productivity. Discover our artificial intelligence services.
View All
Exploring the capabilities of DALL-E 3 and how it pushes the boundaries of AI-powered image generation.
Key highlights and insights from a lecture on neural network training fundamentals delivered at IISc Bangalore.
A beginner-friendly guide to understanding and training Generative Adversarial Networks from scratch.
© Copyright Fast Code AI 2026. All Rights Reserved